Architectural Overview
This document provides a technical overview of the Infrastream v2 platform architecture. It is intended for platform engineers, architects, and technical evaluators who need to understand the inner workings of the core Golang engine, state management, and real-time observability components.
The Big Picture: A High-Performance, Declarative Engine
At its core, Infrastream is a sophisticated automation and abstraction layer built entirely in Go. It implements a Manifest Driven Secure Execution (MDSE) model, transforming cloud management from a procedural task into a fully declarative, version-controlled workflow.
Unlike legacy systems that rely on slow, state-bottlenecked third-party tools (like Terraform), Infrastream executes directly against Google Cloud APIs. This enables massive horizontal scalability and real-time execution feedback.
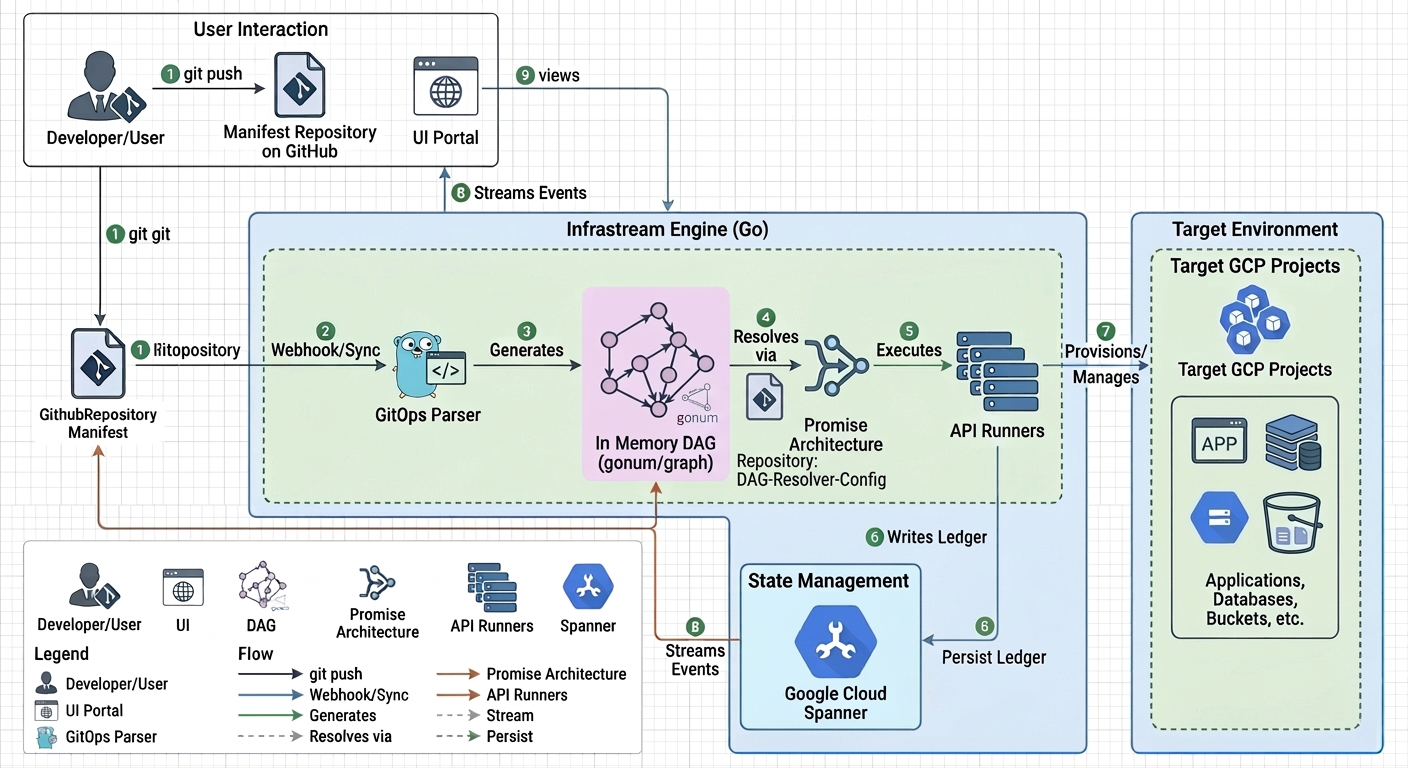
JIT Graph Resolution & Promises
The heart of the engine is its Just-In-Time (JIT) directed acyclic graph (DAG) resolution.
When a deployment is triggered, the engine parses all YAML manifests and constructs a massive in-memory graph using the gonum/graph library. Instead of relying on a slow string-interpolation engine to pass variables between resources, Infrastream uses a strictly typed Go Futures/Promises architecture.
When Resource A needs the generated ID of Resource B, it holds a Promise for that value. The engine automatically topo-sorts the graph and executes the resources concurrently. As Resource B finishes provisioning via the Google Cloud API, it fulfills its Promise, instantly unblocking Resource A in memory. This allows the entire infrastructure topology to be resolved and executed in a single, blistering-fast pass.
MetaGroups and Transparent Gating
Not all infrastructure relationships are physical dependencies. Often, deployments require strict logical orchestration. For example, you may want to guarantee that an entire Organizational Unit (and its security policies) is fully provisioned before any underlying Environments or Projects begin deployment.
Infrastream handles this via MetaGroups. A MetaGroup is a virtual node in the graph that represents a collection of resources. The engine injects LOGICAL structural edges into the execution graph between these MetaGroups and their dependents. This enforces strict execution boundaries—creating an impenetrable "gate" that pauses downstream execution—without cluttering your actual Google Cloud environment with dummy "wait" resources.
The Spanner Data Model (The Time Machine)
To guarantee enterprise-grade reliability, auditability, and concurrency, Infrastream uses Google Cloud Spanner as its central state backend. The platform treats infrastructure state as an append-only, immutable ledger spread across three primary tables: States, StateDependencies, and RunEvents.
Engineering for Scale:
- Bit-Reversed RunIDs: To prevent database write-hotspotting during massive concurrent deployments,
RunIDs are generated using bit-reversed sequences. This ensures that thousands of simultaneous writes are evenly distributed across the global Spanner fleet, unlocking limitless horizontal scaling. - Temporal Graph Reconstruction: Because
RunIDs are not sequential, the engine uses advancedARRAY_AGGSQL grouping based on real-timeStartedAttimestamps to reconstruct the exact topological state of your infrastructure at any given millisecond in history. This underpins the platform's "panic-proof" disaster recovery capabilities. - Vector Embeddings: The ledger natively stores
StateEmbeddingvectors generated via Vertex AI, allowing the system to perform semantic searches and topological "blast-radius" analysis natively within the database.
gRPC Streaming Architecture
The platform prioritizes deployment confidence through absolute transparency.
As the Engine executes the graph and writes to the Spanner ledger, it simultaneously pushes RunEvent deltas into asynchronous Go channels. The Infrastream Portal consumes these channels and multiplexes them out to connected web clients via gRPC server-streaming.
This means that as a database is provisioning, or a Cloud Run service is rolling out, the visual graph in your browser updates in real-time, providing immediate feedback on node statuses (PENDING, CREATE, STALLED) without ever needing to refresh the page.
Strategic Flexibility: Compute Abstraction
A core architectural principle of the platform is the abstraction of the underlying compute service from the application itself. A containerized application is not permanently tied to the compute platform it was first deployed on.
Compute abstraction means that the exact same containerized application can be deployed to Google Kubernetes Engine (GKE), Cloud Run (serverless), or a traditional Compute Engine VM indiscriminately, often by changing a single line in a manifest file.
The Engine automatically handles all the underlying complexity:
- Networking: It ensures the application is correctly connected to the service mesh and can communicate with other services, regardless of where it runs.
- Load Balancing: It configures the appropriate ingress and load balancing for the chosen compute target.
- Security: It applies the same granular IAM permissions and security policies to the application's identity.
- Observability: It provides consistent logging, monitoring, and tracing for the service.
This is achieved via the spec.target field in an Application or ExternalApplication manifest. By changing this single field, an engineering team can seamlessly migrate a service between compute platforms to optimize for cost, performance, or operational requirements, without any changes to the application code. This provides a profound strategic advantage, future-proofing the architecture and enabling continuous optimization.